
It worked!
Clockwise and anti-clockwise beams though the ring with minimal tweeking of the focus and steering parameters. Yay!
It worked!
Clockwise and anti-clockwise beams though the ring with minimal tweeking of the focus and steering parameters. Yay!
A few days ago I built a radio receiver out of junk, because my usual radio had died a death and I wanted to listen to a specific part of the shortwave bands around 3.5 – 4 MHz.
Last night I scanned up and down the band and located what sounded like a fax transmission, a short while later and I’d recorded several minutes of the signal. A litter later still and I’d decoded it using some software I wrote nearly 10 years ago.
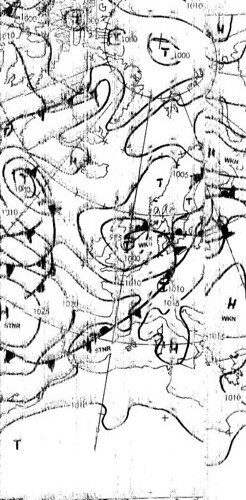
It looks a little messy, but it is quite obviously a weather map showing iso-bars and weather fronts over the Atlantic, the UK and Europe. Not bad for random DIY experiments.
I returned from a Canadian conference had barely a day and a weekend to recover from jet-lag before the kickoff of IVESC in London. IVESC ended on Wednesday, Thursday was a mad rush to arrange stuff before the Boss heads off to India for the rest of the month. Friday was a one-day meeting elsewhere in London, I only made half of this due to the Great British Beer Festival attendance the night before.
No more conferences this month, please!
Some notes:
Oh look. Another conference I’ll be at. Not until November though.
Between gaps and breaks in the clouds I managed to record pretty much the whole eclipse. The filter I used gave a slight ghoating to the edge of the sun, making it look out of focus.

My luck held out and there were just enough gaps in the cloud to catch the start and maxima of the eclipse. It is pretty much solid cloud now, so I’m not going to see the moon leaving the sun. I’ve taken about a dozen photographs of the progress of the moon across the sun – I’ll post them here when I’ve cropped and fiddled with them.